Modellierung
Wer hier eine Generalabrechnung mit oder einen Lobgesang auf die UML erwartet, wird leider enttäuscht werden – auch, wenn die UML beispielhaft erwähnt wird. Hier solle es um Modellierung im Allgemeinen und im Besonderen in der Software-Entwicklung gehen.
Table of Contents
Definition
Ein Modell ist eine Nachbildung eines Originals. Ob das Original zum Zeitpunkt der Modellbildung existiert oder nicht ist bei der Beurteilung, ob etwas ein Modell ist, unerheblich. In allgemeinen wird man jedoch einen Zusammenhang mit der Absicht feststellen, die dazu führt, dass ein Modell erarbeitet wird - aber dazu später (vgl. Abschnitt: Anwendung).
Darüber hinaus stimmt eine Modell im Allgemeinen nicht in allen Eigenschaften mit dem Original überein1 sondern beschränkt sich darauf, die für die Verwendung des Modells notwendigen Eigenschaften mit hinreichender Genauigkeit darzustellen.
Das mag für einen Neueinsteiger in das Thema Modellierung erst einmal recht abstrakt klingen. Jedoch lohnt es sich bei der Betrachtung von Modellierung erst ein mal ein paar Schritte zurück zu treten, um zu verstehen, was man denn wirklich treibt, wenn man modelliert.
Anwendung
In der Systementwicklung, zumindest von Software Systemen, gibt es drei wichtige Anwendungen für Modelle:
Erkenntnisgewinn
Wenn man sich einer Problemdomäne neu nähert hat man im wesentlichen die folgenden Aufgaben zu bewältigen:
- Man muss die wesentlichen Begriffe der Problemdomäne finden.
- Man muss verstehen, in welchem Verhältnis die gefundenen Begriffe zueinander stehen. Diese Struktur ist in der Regel weitaus wertvoller als die pure Auflistung der Begriffe.
- In Problemdomänen, deren Komplexität aus der Vielfalt der Begriffe erwächst, findet man oft Taxonomien, die – mit hinreichender Vorsicht2 – bei der Modellbildung zu beachten sind.
- Auch wenn es etwas in Vergessenheit zu geraten scheint, wäre bei einem objekt-orientierten Herangehen auch festzulegen, welche Zuständigkeiten bei welchem Begriff liegen3.
Vielleicht etwas plakativer: Beispielsweise ein UML Anwender erstellt Klassendiagramme und beschreibt Use Cases inklusive Verhalten. Wenn man dazu ein Werkzeug verwendet, dass es einem leicht macht, Änderungen umzusetzen, so kann man sich damit das Verständnis für ein neues Themengebiet – entschuldigung, eine neue Problemdomäne – inkrementell erarbeiten. In dieser Form von Erkenntnisgewinn liegt ein wesentlicher Wert der Modellierung.
Dokumentation
Oft wird ein Modell zur Dokumentation des Originals verwendet. Der Nutzen entsteht in der Regel dadurch, dass das Modell in einer Form erstellt wird, die sich leichter erschließen lässt als die Form des Originals – sei es, weil das Modell solche Details ausblendet, die für das Problemverständnis4 nicht notwendig sind, oder weil die Darstellung des Modells eingängiger sein mag als die Erscheinung des Originals – vgl. Diagramme und Quelltext. Insgesamt ist ein Modell sicher gut geeignet, um Wissen über das Original zugänglich zu machen und, z.B. in einem Team, zu verbreiten.
In der Softwareentwicklung ist es nun leider oft so, dass in Analogie zu physischen Modellen, davon ausgegangen wird, dass die Erstellung eines Originals anhand eines vorgegebenen Modells in der Art erfolgen muss, dass das Original vollkommen neu, allerdings unter Beachtung der Modellvorlage, zu erstellen sei. Außerdem ist das Verhältnis von Modell und Original in der Software-Entwicklung etwas verzwickt (vgl. Abschnitt: Erstellung oder Transformation), so dass in der Praxis oft der Zusammenhang zwischen Modell und Original verloren geht, also die Dokumentation veraltet. Statt also ein formales Modell zu erstellen, dass zur Automatisierung im Entwicklungsprozess weiter verwendet wird, entsteht eben nur Dokumentation.
Herstellung
Es ist ja nicht untypisch, beim Entwurf neuer Produkte zunächst Modelle zu erstellen, die dazu dienen ausgewählte Produkteigenschaften im Vorfeld festzulegen oder zu verifizieren. Im Gegensatz zum Produktionsprozess von physischen Gütern muss man in der Software-Herstellung kein vollständig neues Werkstück nach Vorlage eines Modells oder Entwurfs herstellen. Vielmehr arbeitet man in der Softwareentwicklung mit der Beschreibung eines Systems, die nach und nach mit mehr Details angereichert wird, bis alle Details festgelegt sind, um das System „auf die ausgewählte Plattform setzen“ zu können. Daraus erwächst die Möglichkeit genau solche Details, die sich systematisch ergeben, automatisch anzureichern.
Konkret: Werden in einem Klassenmodell Entitäten modelliert, dann entscheidet man einmal, wie die Persistenz von Entitäten implementiert wird und kann dieses Detail systematisch auf alle Entitäten im Modell anwenden. Hinter der Aussage „ist eine Entität“ verbergen sich also Unmengen technischer Details, die allerdings aus dem Modell weg abstrahiert sind.
Es sind folglich zwei Mechanismen, die Modelle bei der Herstellung von Software wertvoll machen:
- Abstraktionen, durch die man es vermeiden kann, wiederkehrende Sachverhalte wieder und wieder zu beschreiben (DRY).
- Automatismen, die verwendete Abstraktionen erkennen und in der Lage sind, das Modell zu konkretisieren.
Beispielsweise ist @Entity eine bekannte Abstraktion für Persistenz,
die von einer JPA Implementierung automatisch umgesetzt werden kann.
Wenn zu einer Problemdomäne die richtigen Abstraktionen und dazugehörende Umsetzungsmechanismen vorliegen, kann man das Modell für eine Problemlösung klein halten und damit den Produktivitätsgewinn bei der Herstellung von Systemen deutlich steigern.
Erstellung oder Transformation
Wer sich neu mit dem Thema der Modellierung in der Softwareentwicklung befasst ist sich oft sehr sicher, dass das Original, welches zu modellieren ist, der Quell-Code des Zielsystems sei. Allzu oft werden auch noch die Diagramme, die häufig bei der Modellierung entstehen, mit dem Modell identifiziert. Zwei Umstände mit denen es zunächst aufzuräumen gilt. Beginnen wir mit den Diagrammen eines Modells:
Diagramme als grafische Notation
Das Verhältnis eines Diagramms zu dem beschriebenen Modell ist bzgl. seiner Abstraktion gut vergleichbar mit dem Verhältnis einer Implementierung zum Algorithmus: Quick-Sort bleibt Quick-Sort, egal ob ich es in C, JavaScript oder Haskell implementiere! Ganz ähnlich ändert sich ein Ablauf auch nicht dadurch, dass ich ihn als Aktivitätsdiagramm der UML oder als Nassi-Shneiderman-Diagramm darstelle. Auch die Beziehungen zwischen fachlichen Entitäten sollten davon unberührt bleiben, ob man sie in einem UML Klassendiagramm oder in einem ER Diagramm aufzeichnet.
Betrachtet man das Verhältnis anders herum, so kommt man zu dem Punkt, dass Diagramme ein hervorragendes Mittel bieten, um gezielt einzelne Aspekte eines Modells zu beleuchten. Betrachtet man Diagramme als Modell, so verliert man die wertvolle Anwendung in der Herstellung des Systems. Diagramme als reine Bilder eignen sich höchstens zum Erkenntnisgewinn oder zur Dokumentation.
Modelle und Meta-Ebenen
In diesem Zusammenhang möchte ich zunächst auf die Meta-Ebenen M0–M3
der OMG eingehen. Die OMG hat sich entschieden Modelle bezüglich der
Relation „ist Instanz von“ gegeneinander abzugrenzen. Diese Abgrenzung
ist hervorragend geeignet, um in der Frage, was „Softwerker“
(Architekten, Designer, Entwickler, ) im Grunde treiben, voran zu
kommen.
Beginnen wir hierzu mit der Frage, wo denn der Quelltext eines
Programms anzusiedeln ist. Die OMG beantwortet das klar mit: M1
bzw. der Modellebene. Gut, verwenden wir also die Aussage, dass ein
konkretes Programm auf der Metaebene M1 anzusiedeln ist, als
Ankerpunkt. Als nächstes wenden wir uns der Frage zu, wovon unser
fiktives Programm denn eine Instanz ist. Gemäß OMG müssen wir dazu
feststellen, welche Sprache verwendet wurde, um das Programm zu
(be)schreiben. Im Modellierungsumfeld wäre das natürlich UML –
schließlich verwendet man UML, um ein konkretes System zu
beschrieben. In der Praxis stellt man aber auch häufiger fest, dass
Programmiersprachen verwendet werden, um lauffähige Softwaresystem zu
erstellen. Wie dem auch sei, gemäß der Abgrenzung der Metaebenen durch
„Instantiierung“ müssen wir alle Sprachen und Notationen, die
verwendet werden, um konkrete Systeme oder Programme zu beschreiben,
auf der Metamodellebenen M2 ansiedeln. In diese Richtung kann man
nun weiter forschen und nach dem Metamodell von UML oder z.B. auch
Lisp und anderen Programmiersprachen fragen. Die OMG beantwortet das
mit der MOF, der Meta Object Facility, die als Metametamodell auf
der Ebene M3 angesiedelt ist. Als solche kann sie nicht nur zu
Metamodellen wie UML, oder auch Java, instantiiert werden. Praktischer
Weise kann MOF sich selbst beschreiben und deswegen als Instanz ihrer
selbst gelten. Damit hat man dem unendlichen Fragen nach weiteren
Metaebenen einen Riegel vorgelegt.
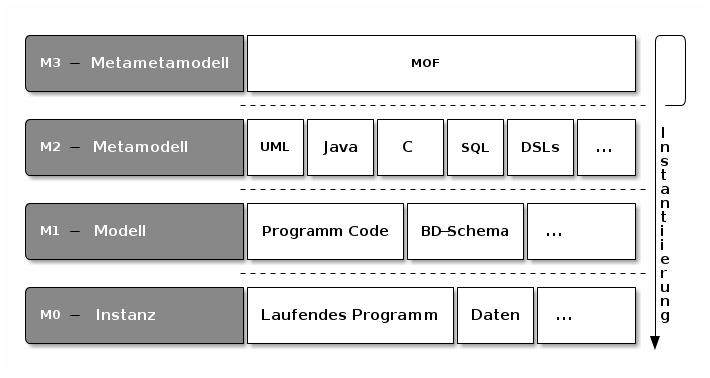
M0, die
Ebene der „endgültigen“ Instanzen. Hier haben wir konkrete Dinge vor
uns, die nicht mehr instantiiert werden. Ziel des Entwicklungsprozess
ist es, den Weg auf diese Ebene frei zu machen.
Oder weniger theoretisch: Als Anwender einer Software ist es mein Ziel, ein laufendes Programm zu benutzen, damit Daten zu erfassen womöglich zu bearbeiten und meist auch zu speichern. Hierin liegt der Wert für den Anwender. Bisweilen bekommt man den Eindruck man bezahle für den Erwerb des „Programms“. Aber wer beschäftigt sich schon damit, den Source-, Byte- oder Maschinen-Code zu lesen, den er gerade gekauft hat? Wohl die Wenigsten. Vielmehr schätzt man, dass man eine – wenn auch höchst formale – Beschreibung von komplexen Vorgängen erworben hat, die eine Maschine dazu in die Lage versetzt, dies Vorgänge auch durchzuführen. Der Entwicklungsprozess hat also sein Ziel erreicht, wenn auch eine Maschine, ohne jegliches Gemeinverständnis, mit der Beschreibung klar kommt.
Das Original, das man modelliert ist also das laufende System, nicht jedoch das ausführbare Programm und schon gar nicht der Source Code.
Immer genauer, bis es passt
Wenn weder das ausführbare Programm noch sein Source Code das Original sind, zu dem man ein Modell erstellt, dann muss man anders erklären, warum Modellieren, Generieren und Transformieren so wertvolle Tätigkeiten sind:
Der Weg zu einem ausführbaren System ist schwer. Hat man das erst mal,
dann ist der Sprung auf die M0 Ebene, also zum laufenden System,
vergleichsweise5 einfach.
Nun ist Generierung auf der Modellebene nichts unglaublich neues. Man hat schon sehr früh damit aufgehört, den Maschinen Code direkt in den Speicher von Computern zu schreiben, um ein Programm laufen zu lassen. Denn auch in Assembler kann man kein direkt lauffähiges Programm schreiben. Assembler muss erst in Maschinen Code übersetzt werden, bevor man ihn ausführen kann – auch wenn das Übersetzen in diesem Fall eine recht einfache Transformation ist.
Wer etwas in der Geschichte der Software-Entwicklung kramt, wird schnell finden, dass der damalige Übergang von Assembler zu Hochsprachen einen enormen Produktivitätsgewinn gebracht hat. Nicht verwunderlich: Hochsprachen, selbst C6, sind doch deutlich abstrakter als Assembler. Die Compiler oder Interpreter fügen dann alle Details hinzu, die fehlen, damit ein hochsprachliches Programm auf eine Maschine laufen kann. Übrigens sollen auch damals viele Entwickler diesem „modernen Kram“ mit viel Skepsis gegenüber getreten sein. Man verliere doch viel Kontrolle, wenn man Assembler aufgäbe. Genug von Gestern! Wie könnte heute ein einigermaßen automatisierter Entwicklungsprozess aussehen?
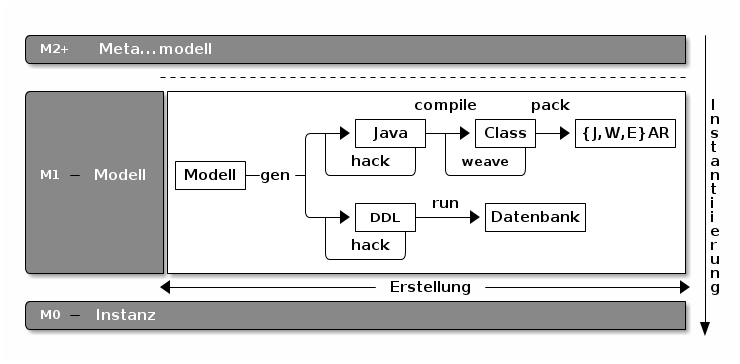
M1
Ebene. Die Instanzen, also die Daten, kommen erst später dazu.
Was aber deutlich wird ist, dass das Arbeiten mit Modellen im allgemeinen Sinne nicht neu ist. Auch ist es nicht revolutionär, ein Modell automatisch in ein anderes Modell zu transformieren. In der Regel nutzt man diesen automatischen Schritt dazu, systematisch wiederkehrende Details in das Zielmodell einzubauen.
Dieses Hin und Her zwischen den Modellen ist (hoffentlich) kein
Selbstzweck. In welche Richtung muss die Generierung gehen und wo hört
man damit auf? Idealer Weise hört man dort auf, wo man das eigentliche
Ziel – den Übergang von M1 zu M0 – oder im Klartext das Laufende System mit nur einem Knopfdruck bekommt. Ein wenig wie Continuous Delivery. Und wo liegt dieser Punkt? Das kann man nicht
allgemeingültig festlegen, denn es hängt von der Plattfrom ab, die
als Zielplattform zum Einsatz kommt. Erst wenn für jedes Detail des
Zielsystems in jeder zu beachtenden Situation klar ist, das weitere
Details von der Plattform zuverlässig aufgelöst werden, ist das
Modell präzise genug.
Wenn ich mich zum Beispiel auf die Java Runtime abstütze, ist mit new FileOutputStream("name") genug darüber gesagt, dass ich eine
Ausgabedatei benötige. Wenige „Stockwerke“ tiefer finde ich womöglich
ein UN!X System und muss deswegen davon ausgehen, dass auf dem Weg zu
meiner Ausgabedatei ein open("name",O_WRONLY|O_CREAT|O_TRUNC) oder
ähnliches liegt. Das sind Details, die die JVM hinzufügt. Nun könnte
man im Betriebssystem nachschauen, was sich hinter open() verbirgt
und so fort.
So kommt man dann von Plattform zu Plattform. Eigentlich ist das nicht verwunderlich, haben wir doch alle gelernt, dass man Probleme mit "Divide and Conquer" solange klein schlägt, bis sie beherrschbar werden. Dadurch bekommt man einen hohen Stapel von Abstraktionen, von denen mache so universell einsetzbar sind, dass man sie selten verändern muss. Die nennt man dann „Plattform“ und viele bauen darauf. Auf jeden Fall hat sich die Automatisierung der Modelltransformationen innerhalb der Modellebene bereits über viele Jahrzehnte bewährt. Und wenn man einen Satz von Generatoren hat, dazu zähle man hier jetzt auch Compiler, Byte-Code-Weaver u.v.a.m., der aus einem hinreichend abstrakten Modell genau die Artefakte erzeugt, die zur der Zielplattform passen, so hat man einen effizienten Entwicklungsprozess. Wenn man diese nicht hat, so kann die Erstellung der passenden Generatoren leicht mühselig werden. Generatoren zu programmieren braucht oft mehr Abstraktion als Anwendungen zu schreiben. Wenn man es aber beherrscht, lohnt sich das.
Noch ein Wort zu UML
Weil UML schon per Dekret universell zu sein versucht, passt sie
meinst nicht perfekt auf spezielle Probleme. Schauen wir aber noch
einmal in die Schicht M2 der Metamodelle und treffen unsere Wahl,
welches konkrete Metamodell wir sonst universell einsetzen
wollen. Versuchen sie mal einer Fachseite einen Geschäftsprozess mit
SQL näher zu bringen, statt mit Aktivitätsdiagrammen – das wird nicht
leicht werden! In den frühen Phasen einer Systementwicklung hat UML
doch ein paar Vorteile:
- Sie bekommen mittlerweile ganz gute UML Werkzeuge von der Stange.
- Mittlerweile hat sich ein vergleichbares Verständnis für die Kerndiagramme der UML so weit verbreitet, dass UML zur Dokumentation und Kommunikation hilfreich ist. Das ist nicht zu unterschätzen.
- Über Sequenzdiagramme können sie oft auch mit Menschen konstruktiv reden, die keine UML Kenntnisse haben. Einige Notationen sind intuitiv genug, wenn man auf diffizile Details verzichtet.
- Im Ergebnis kann man mit UML ohne große Vorbereitung starten, vorausgesetzt man hat mit UML hinreichend Erfahrung.
Daneben ist „Full-Blown UML“ so vielfältig und komplex, dass es einem bei der Generierung eher etwas im Weg als zur Seite steht. Schauen Sie sich mal eine XMI Datei an. Sicherlich ein Prachtwerk an Metaisierung, aber für mein konkretes Problem… sperrig. Darin liegt wohl auch ein bisschen der Nährboden für die Idee sich das passende Metamodell selbst zu schaffen:
Bewegung auf der M2 Ebene – DSLs
ToDo
Lizenz

Über… Modellierung von Marcus Perlick ist lizenziert unter einer Creative Commons Namensnennung - Nicht-kommerziell - Keine Bearbeitung 3.0 Unported Lizenz.
Footnotes:
1 Hätte man eine vollständige Übereinstimmung, dann wäre es eine Kopie und kein Modell.
2 Hier steht die Wartbarkeit im Vordergrund. Will man eine Taxonomie z.B. durch eine Vererbungshierarchie nachbilden, muss man fragen, welche Auswirkung Veränderungen daran auf das System haben und ob diese gewünscht sind. Technische Gemeinsamkeiten sind hier ein schlechter Ratgeber.
3 Dabei dürfen einem Begriff nur die Zuständigkeiten zugewiesen werden, die – vergleichbar einem Naturgesetz – zu ihm gehören. Würde man übergreifende Interaktionen in einem Fachbegriff verankern, so führte das zu einem starren System, dass schlecht an geänderte Anforderungen angepasst werden kann. Was das für übergreifende Interaktionen bedeutet und ob OO alles Löst soll nicht hier diskutiert werden.
4 Es ist dringend zu hinterfragen, ob de das Problemverständnis gibt. Treffender ist es, dass ein Modell eine gewisse Perspektive auf das Original abdeckt. Daher wird man i.d.R. mehrere Modelle benötigen, um alle oder die wichtigen Blickwinkel auf ein Original zu erhalten.
5 In Großen Systemen ist der Betrieb keinesfalls zu unterschätzen. Aber im Regelbetrieb sollte sich die Notwendigkeit an kreativer Leistung in Grenzen halten.
6 Addieren sie mal auf einem 8-Bit Prozessor 162 und 205. Da ist
ein int a=162, b=205; a+=b; eine echte Erleichterung.
Date: May 25, 2014
HTML generated with emacs org-mode & Toxic by [qb]